百度云时序数据库又双叒叕更新啦,这些新功能帮你更好玩转IoT
在万物互联网的时代,世界上的每一个物体每时每刻都在产生着数据,如个人的健康数据、工业设备的状态数据、车联网的实时数据等等。
在物联网蓬勃发展之际,描述物体在时间坐标中的状态信息的时序数据开始变得越来越重要,成为大数据分析、机器学习的重要原料。
因此,存放时序数据的时序数据库,拥有突出的写入性能以及针对时序数据存储和查询的优化,能够解决大部分传感器数据的高并发、高频率的写入存储需求,可谓是天然为物联网而生。
2016年,百度云在天工平台上正式发布了国内首个云端时序数据库产品TSDB,成为百度云全力布局物联网领域的标志性产品。经过两年多时间的发展,百度云时序数据库TSDB已经广泛应用在工业互联网、车联网、智能制造、电气监测、互联网运维监控等领域,并且产品功能和应用场景持续更新。
近日,百度云时序数据库TSDB再次推出一系列新功能,涵盖到私有化环境部署、日历对齐、报表统计等方面,进一步丰富了TSDB的适应环境。下文将逐个介绍TSDB本次推出的新功能,并提供试用地址。
新功能一:私有化部署
近年来,随着物联网应用的兴起,靠近物或数据源头的一侧的边缘计算也开始成为热点。边缘计算通过本地设备实现计算处理、AI推断,大幅提升处理效率,为用户提供更快业务响应。对于行业中一些对实时性、智能性、安全与隐私性比较强的业务,边缘计算可谓是再适合不过了。
为此,低延迟、本地环境部署的场景下成为物联网应用的一种趋势。百度云天工的智能边缘+TSDB-Edge版可以完美契合这种场景的物联网数据存储、端上AI模型执行的需求,并可为用户提供完整的端+云解决方案。
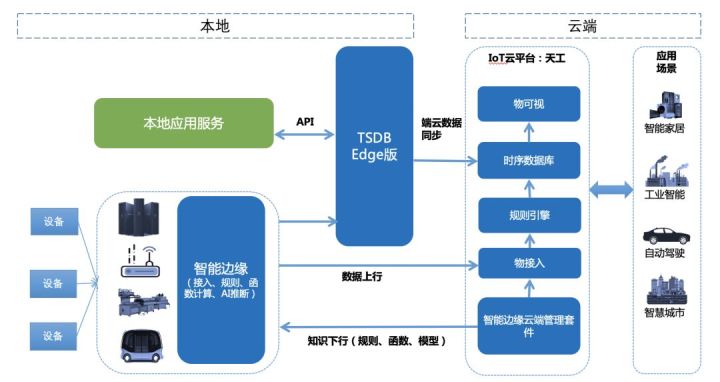
通过百度云天工智能边缘+TSDB-Edge版的解决方案,用户可以轻松实现私有环境的时序数据收发,以及与云端配置的同步。主要能力如下:
-
本地收发+存储:智能边缘完成私有环境下的消息收发,并将接收到的数据转发到TSDB-Edge版。
-
云端配置:智能边缘的转发规则可以由云端配置完成。
-
端云同步:TSDB-Edge版中的数据可以配置与云端同步。
随着百度云时序数据库TSDB私有化环境部署功能的上线,用户们可以在自身本地环境中更加灵活的进行数据存储和分析,大幅提升业务的响应能力。
百度云时序数据库TSDB-Edge版已经开放试用,感兴趣的的小伙伴可以看这里!
(https://cloud.baidu.com/survey/TSDBEdgeApply.html)
新功能二:日历对齐
本次百度云时序数据库TSDB还推出了日历对齐功能。TSDB经过在不同行业用户两年多的使用,百度云也发现了一些有意思的现象。比如,在一些电力领域,通常要以日、月、年为单位计算用电量,而参与计算的开始时间和结束时间不一定是整日、整月或整年。
-
比如,现在是10月26日9:00,查询最近两天的用电量:
-
那么,昨天的用电量是10月25日00:00-10月26日00:00的和值,今天的用电量则是10月26日00:00-10月26日09:00的和值。
基于这种情况,TSDB提供了聚合函数可以按照自然年、月、日、时、分、秒聚合的方法。
在百度云时序数据库TSDB的查询语句中,Aggregator对象中的sampling参数,增加字符‘c’即可。例如,增加“1 dc ”,则计算结果可以按照自然日对齐;增加如“1 yc ”,则计算结果可以按照自然年对齐。具体操作请参考相关页面。
(https://cloud.baidu.com/doc/TSDB/API.html#.E6.9F.A5.E8.AF.A2data.20point)
日历对齐功能的推出,解决了特殊领域的问题,进一步完善了百度云时序数据库产品的功能适用性。
新功能三:报表统计
时序数据库可以很好地存储各种时序数据,不过数据通常需要进行分析和应用才能具有价值。这时,时序数据库与其他技术结合就能够发挥巨大作用。
例如,在物联网很多场景下,无论是环境保护的监控数据,还是各类工业生产设备的监控数据,TSDB都能够实时进行存储。但是通常在环保领域或者工业领域,都是需要及时了解环境状态或者工业设备工作状态的,甚至还需要了解以日、月、年为单位的运行状态。这就需要从时序数据库中的数据进行统计,并能进行日报、月报,甚至是实时统计。
举一个真实的案例:
-
在某个环境焚烧厂中,每分钟会上传该时段SO2的排放量,工作人员需要知晓每个小时SO2的排放总量,根据排放总量来灵活安排生产任务,并希望通过这些数据来做数据分析工作。
针对这种典型的应用场景,百度云采用时序数据库TSDB+流式计算的方式来满足业务需求。比如:
焚烧厂上传的SO2排放量数据,写入到TSDB中以如下形式存储原始数据:
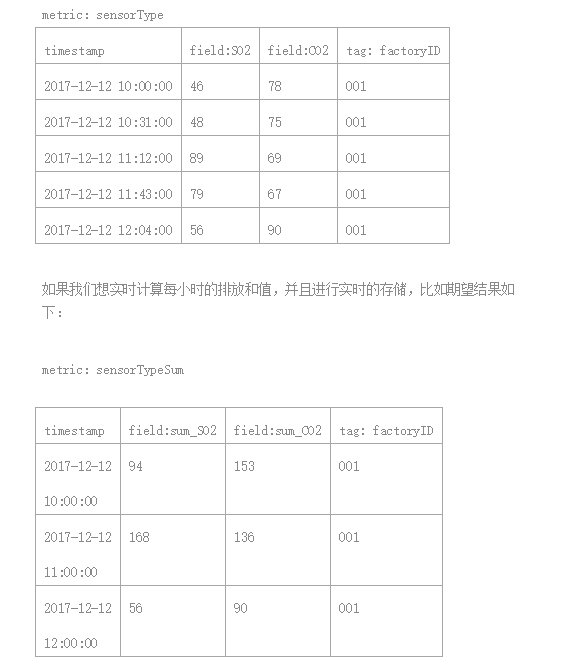
那么,我们需要在流式计算中进行简单配置,流式计算会将TSDB中上传的原始数据实时的计算成期望的聚合值,具体配置如下:
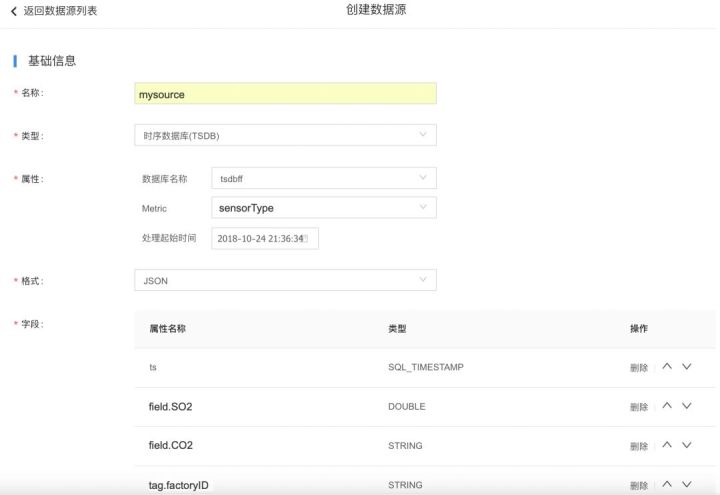
1. 首先,配置TSDB的实例为流式计算数据源,系统会自动探测metric下所有的域和tag,并且自动生成各个字段。
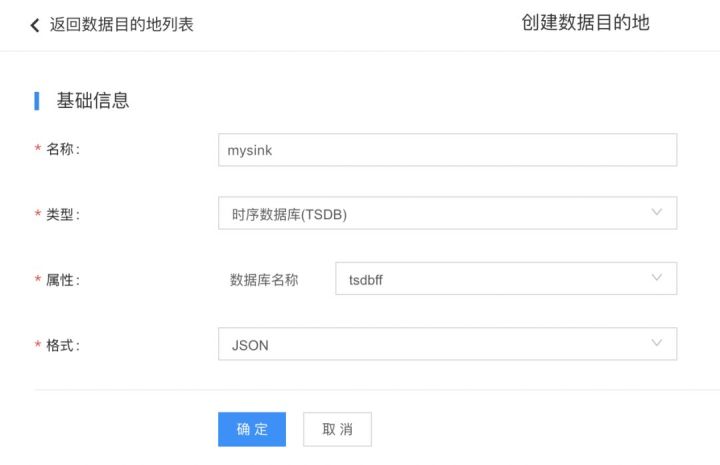
2. 第二步,需要配置TSDB实例为流式计算的数据目的地。
3. 第三步,创建任务。根据上述需求,SQL任务可以这样创建:

以上都配置完成后,流式计算就会实时将写入TSDB中的数据计算好,并且以多域的方式写回到TSDB中名为sensorTypeSum的度量中去,两个域分别为sum_SO2和sum_CO2,直接查询这个度量,就能得到聚合后的统计值了。
至此,通过简单的配置,用户就可以实现对焚烧厂上传的SO2排放量数据进行实时统计,并可以轻松形成各种报表。
提醒各位开发者:目前,百度云流式计算目前还是公测期,想使用的小伙伴请在这里申请!
(https://cloud.baidu.com/survey/streamingApply.html)
')}
