云计算时代的到来给人们带来了很多便利,同时也带来了挑战。比如,硬件环境更加复杂、设备多样、处理难度大,运行的平台系统更加多样化,需要更广的知识面,对运维安全要求也更高,所以在云环境下,我们需要对云运维平台进行可视化管理。

运维可视化核心是将所运维的服务、资源、设备的状态和正在发生的事件通过可视化的手段呈现出来,指导运维人员或者产品研发人员做出正确的运维决策。某种程度上,云平台的运维与可视化相辅相成,可视化程度越高,运维就越简单,运维效率也就越高。
在云运维的工作范畴中,实时监控对故障的发现和诊断起到至关重要的作用。今天,我们以私有云监控中的一个重点场景——内网监控为例,来介绍可视化的重要作用(内网指的是一个企业的内部网络,包括机房内部网络和机房间的网络)。
异常事件可视化
当运维工程师发现自己负责的系统出现故障时,检查网络连接是否有异常,是故障排查流程当中的标准步骤。在这个场景中,工程师需要知道自己的系统所在的机房以及所依赖的网络通路是否存在故障,所以希望内网监控系统提供一个网络故障概览,展示给定的时间段中相关机房的异常事件。
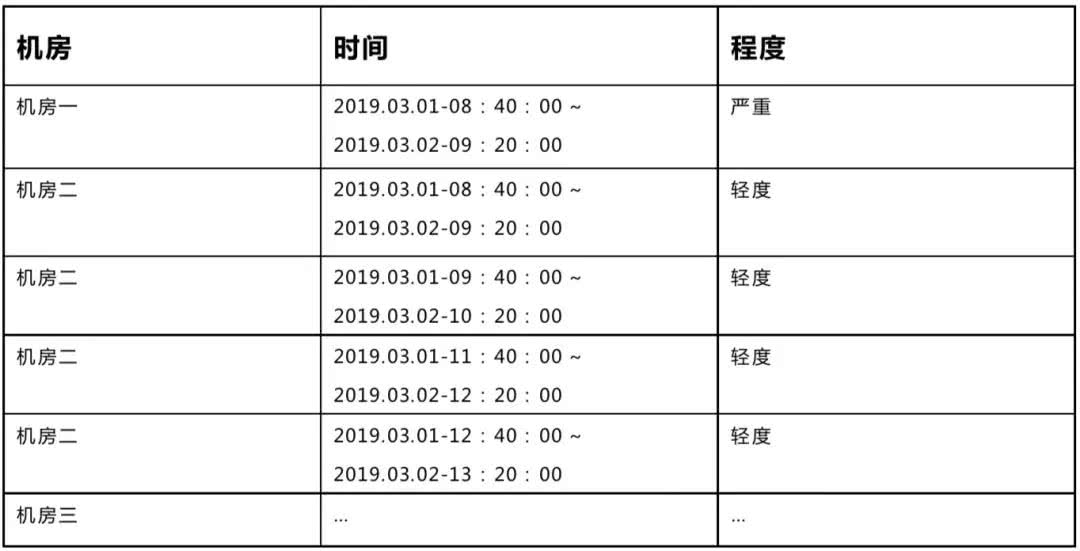
最简单的方式是将所有的网络故障展示在表格当中。
如上表所示,每一行代表一个故障事件。
第一列表示故障关联的机房
第二列表示故障的起止时间
第三列表示故障的严重程度
这种展现方式存在以下三个问题:
不能第一眼看出哪些故障严重,哪些故障轻微。
不能直观感受到每个故障的持续时长。
很难知道在某一时刻哪几个机房同时存在故障。
当时间段很长,筛选出的故障事件很多时,表格会变得很长,就更加不利于工程师了解网络状况。
为解决以上问题,我们需要在机房、时间、 程度三个维度上都能直观的展示故障事件。从时间跨度来想,有点像事件流的感觉,似乎可以用事件流图来展示。
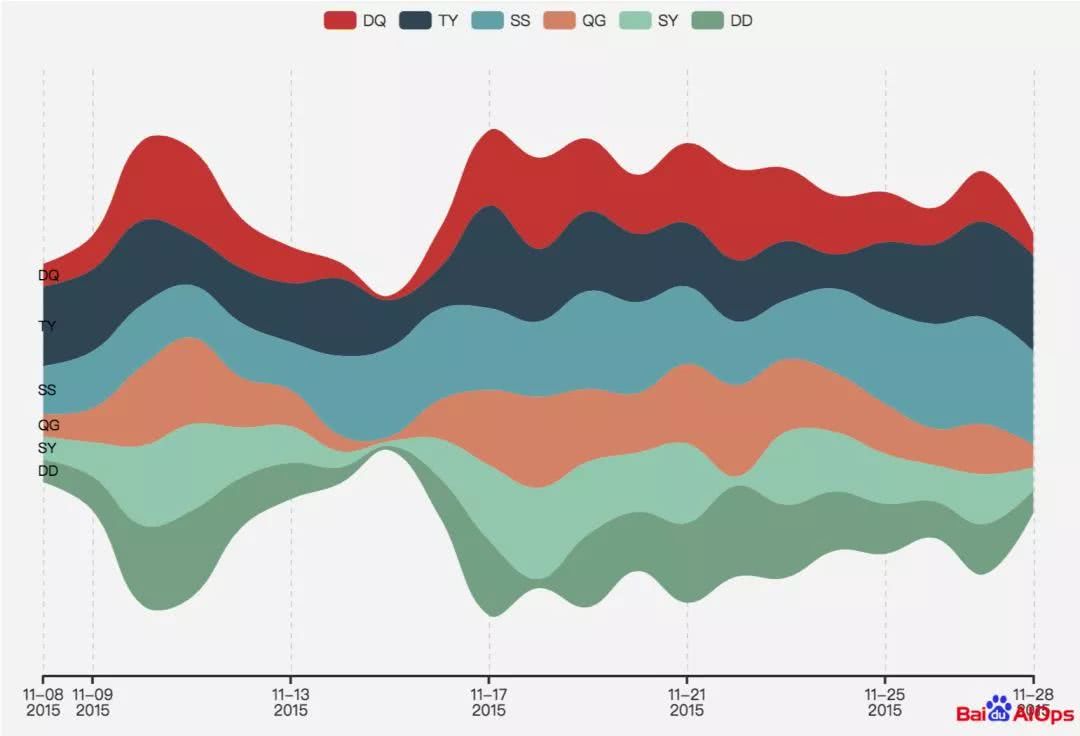
图1 事件流图
如图1所示,事件流图用一条事件河流来表示事件。河流被横向切分为若干条色带,每条色带代表一个类别的事件。色带的高度(河流的宽度)代表在某个时刻,各类别包含事件的个数。事件越多,河流越宽,反之越窄。
这种事件流图适合展示在一段时间内事件群体的统计变化,而我们需要能够展示每个事件的个体信息。因此,我们对事件流图作了几个修改:
每个故障事件用一个矩形条表示,矩形条左右两边的位置对应事件的起止时间。
矩形条的颜色用来区分事件的严重程度,而不是事件的类别。
关联到某一个机房的故障事件矩形条放在河流的同一个高度位置。如果事件在时间上能完全错开,则将矩形条左右放置。如果事件在时间上有重叠,则拓宽机房所占河流的宽度,将矩形条上下放置。

图2 异常事件流图
图2展示了我们的事件流图方案。
图中展示了三个机房的异常,其中机房一有1个严重的异常事件(用红色来标识),这个异常事件是一个时间跨度比较长的严重异常事件。机房二有4个轻度的异常事件(用黄色标识),这4个异常是时间跨度比较短的轻度异常事件,机房三有12个轻度的异常事件(用黄色标识),这12个异常事件中也有三个时间跨度比较长的时间。如果鼠标放置在异常事件矩形块上,就能查看哪个机房出现异常。
通过这个图,工程师可以很方便地看到每个机房的每个故障事件的详细信息,比表格的方式直观得多。
总 结
事件流图,从机房、时间、异常程度三个维度都能直观的展示故障事件,帮助工程师快速查看异常情况。其实,事件流图还可以用于展示变更事件,甚至可以将变更事件与异常事件组合,让工程师能一眼查看异常事件可能是由哪些变更事件引起的。
我们从智能运维场景中抽象出一些可视化组件,比如这里的事件流图组件,再通过前端工程化工具把这些子元素串联起来,构建出前端统一展现层框架,后面我们会逐一介绍这些可视化组件与框架其他细节。
关于智能运维的后续文章,还请持续关注百度云微信公众号。有问题可微信后台留言,我们随时解答。
')}
