天工TSDB又添利器,SQL挖掘更多数据价值
经过二十多年的发展,伴随着AI、大数据、云计算等技术的突飞猛进,物联网的价值逐渐凸显,成为了互联网和传统公司争相布局之地。而作为物联网领域数据存储的首选,时序数据库也进入人们的视野。

百度智能云在时序数据库领域布局较早。早在2016年7月,百度智能云就在其天工物联网平台上发布了TSDB,这是国内首个多租户的分布式时序数据库产品,能够支持制造、交通、能源、智慧城市等多个产业领域。2018年5月,百度智能云天工平台在TSDB上加持了SQL引擎,成为首个支持SQL的云上时序数据库服务,至此用户可以更加熟悉方便地对数据进行操作,同时充分利用SQL函数的计算能力,挖掘数据价值。
本月,百度智能云天工TSDB的SQL引擎正式对外开放,所有套餐用户均可使用SQL查询功能。接下来,本文会从以下几个方面带你全方位的了解百度智能云天工TSDB上的SQL生态。
为什么TSDB需要SQL支持?
百度智能云天工TSDB一直有完整的API接口查询支持,在此基础上,现在又正式开放了SQL引擎,其中的原因有以下几个方面:
首先,SQL的学习成本较低,对于技术人员而言,更符合日常使用习惯;即使是非技术人员,学习起来也很容易上手,可以省去熟悉API的学习成本。
其次,从可支持查询的场景而言,因为API接口的格式相对固定,虽然可以支持绝大部分的查询场景,但是相对来说,不如SQL可表达的语义丰富,一个典型的场景是TSDB中多个metric的联合查询,使用SQL中的join即可很方便的实现。
再者,SQL生态可以更方便的对接BI系统,通过SQL查询功能,TSDB数据库可以和现有的BI平台实现无缝对接。
最后,无论是传统的数据存储服务或者计算框架,都有自己对应的SQL生态,例如HiveSql,SparkSql。百度智能云天工TSDB作为专注于时序数据的存储服务,也应该有对应的SQL生态。
TSDB SQL引擎能做什么?
TSDB支持标准ANSI SQL语义,查询数据的体验与传统的SQL体验一样简洁明了。用户使用TSDB的SQL引擎,可以像API接口一样访问TSDB的时序数据,同时还可以利用SQL强大的计算函数能力。
让我们先通过一个简单的示例,来了解下如何在TSDB上使用SQL:
假设有一个智能电表监控的物联网集成方案,采集了智能电表的各个监控点的数据。在TSDB中这样组织(如下图),metric为SmartMeter,表示TSDB存的是智能电表的数据,每个电表有power和current两个域(field),用两个tag,即meterID和city,来代表每个数据点来自哪个电表ID和城市。电表每5s上传一次功率值和电流值。
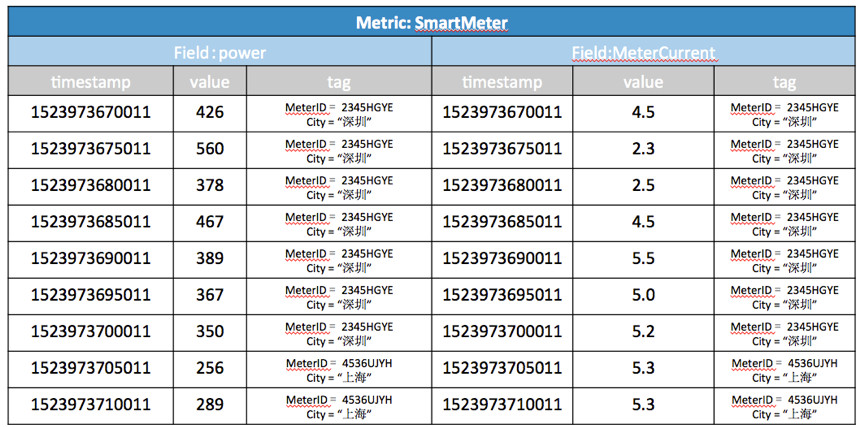
可以将上表看成一个二维表,针对二维表来写SQL语句。
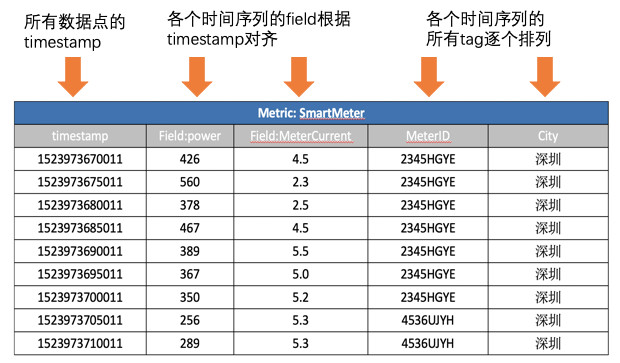
做完这些基础工作后,我们来看具体场景下如何应用SQL语句来解决问题。
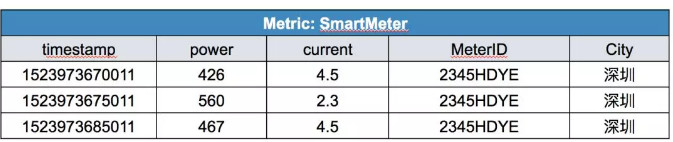
➤ 应用场景一:要过滤功率值大于400、电流值小于5,电表ID为2345HDYE的数据:
select timestamp, power, current,MeterID, City from SmartMeter where power > 400 and current<5 and MeterID= ‘ 2345HDYE’。
得到数据如下:
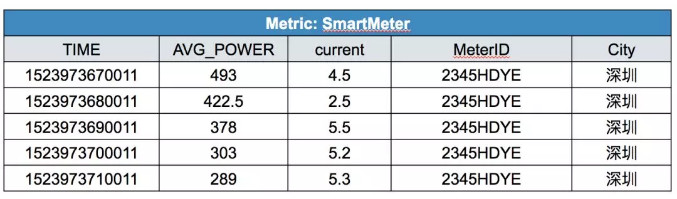
➤ 应用场景二:电表ID为2345HDYE的电表中,返回每10秒的功率平均值:
select time_bucket(timestamp, ’10seconds’) as TIME, avg(power) as AVG_POWER, current, City from SmartMeter groupby time_bucket(timestamp, ’10 seconds’) order by TIME;
得到数据如下:
从上面的示例可以看到,用户可以像访问RDS一样使用SQL访问TSDB,支持字段过滤,排序,分组,聚合等常用操作。同时因为时序数据的特性,还可以使用time_bucket来计算带时间窗口的聚合函数。
除了以上示例中所提到的,TSDB SQL的查询功能尽可能的和API查询接口对齐,这样用户就可以在两种查询方式上灵活切换,具体包括:
▷ 所有类型的域的查询:TSDB现在支持整型、浮点型、字符串类型和Bytes类型。
▷ 对于原始数据的扫描、支持filter、orderBy、limit等常用语义。
▷ 对于函数计算场景,支持SUM、AVG、COUNT等常用聚合函数,并支持按照tag、时间窗口等分组;同时支持包括floor、abs等常用的计算函数。
除了以上和API接口保持一致的功能之外,TSDB SQL还支持:多metric的join操作,可用于不同metric之间的联合查询。
TSDB SQL引擎性能优化
数据查询引擎的架构一般分为存储层和计算层,前者负责对接数据源和原始数据的读取;后者负责生成查询计划并做优化,以便更高效地从存储层获取数据。在这一部分,我们将介绍TSDB SQL引擎在计算层进行的查询优化方面的工作。
计算层对查询计划的优化主要分为:基于成本的优化(Cost-Based Optimization)和基于规则的优化(Rule-Based Optimization)。使用CBO时,计算层会在多个查询计划间挑选一个成本最低的查询计划执行,在评估成本时可能需要用到存储层提供的一些数据相关信息。而使用RBO更多的是使用一些规则,在对原始查询计划做等价变换的基础上,不断优化出性能更优的查询计划,其中比较常见的规则有谓词下推,列裁剪等等,这里以谓词下推为例作下简要介绍。
谓词下推(Predicate Pushdown)的思路是通过将SQL语句中WHERE 子句中的谓词移到尽可能离数据源靠近的位置,从而能够提早进行数据过滤并有可能更好地利用索引。下面通过一个例子来说明:
继续利用上一章节中的场景,假设我们除了SmartMeter这个metric之外,还有另外一个metric来记录电表的温度:
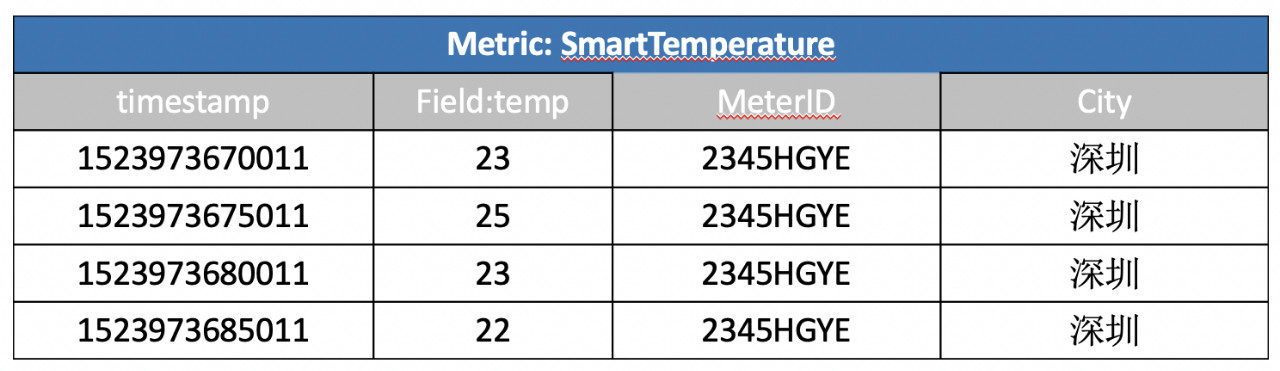
现在需要join这两个metric来对特定的电表进行联合查询,SQL语句如下:
select * from martMeter joinSmartTemperature on SmartMeter.MeterID = SmartTemperature.MeterID where MeterID= ‘ 2345HDYE’;
针对上述的SQL语句,会生成如下左图的原始查询计划:虚线以上可以认为是计算层生成的查询计划,虚线以下对应存储层的数据源。这个查询计划使用TableScan算子将两个metric的数据扫描出来,然后完成join操作,并在join之后的结果上做“MeterID= ‘ 2345HDYE”的条件过滤,最后输出结果。
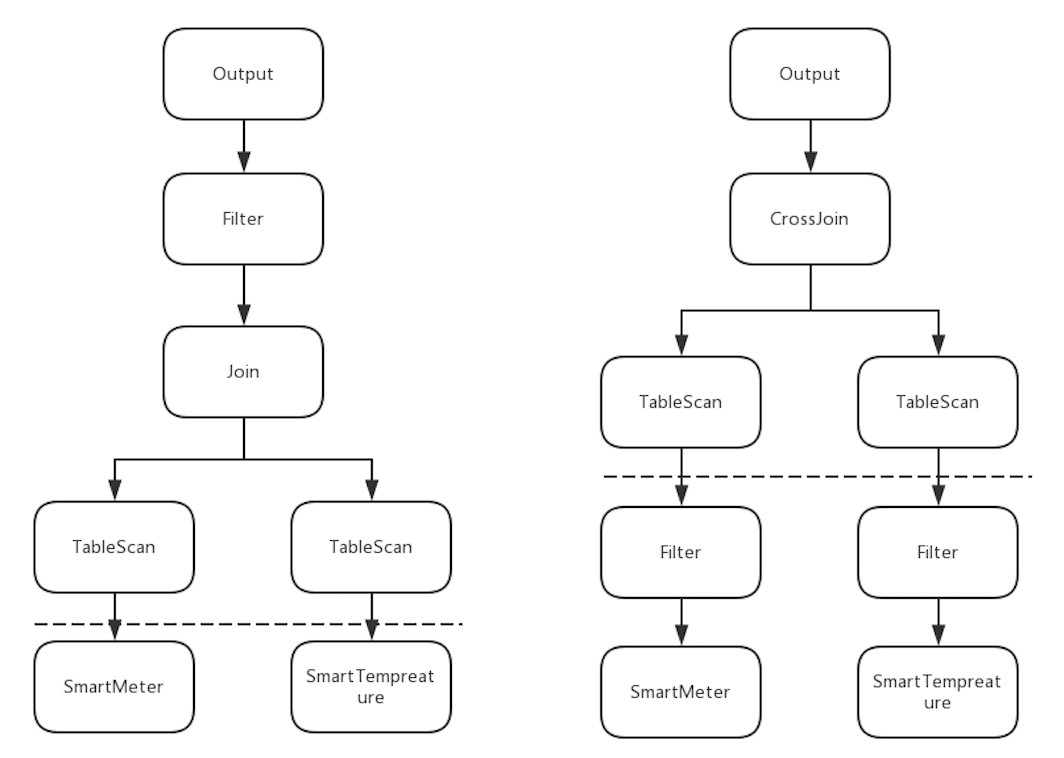
而右图是经过”谓词下推”优化之后的查询计划,可以看到,filter算子也就是“MeterID = ‘ 2345HDYE”的过滤,被下推到了TableScan算子下面,这样的调整有什么好处呢?
首先,TableScan算子不再需要对原始数据进行全表扫描,只需要获取经过“MeterID = ‘ 2345HDYE”过滤之后的数据,从数据量来说得到了缩减。
其次,如果SmartMeter和SmartTempreture作为数据源,本身就对MeterID这个字段的过滤有优化的话,查询性能就能得到进一步的提升,这也就是上面提到的更好的利用数据源的索引。
最后,由于TableScan输出的数据量减少了,需要join的数据量也就减少了。
可以看到,谓词下推是通过尽可能移动过滤表达式至靠近数据源的位置,来减少算子之间需要传递的数据量,进而优化查询计划。TSDBSQL现已支持timestamp,field以及tag上绝大部分的谓词下推,并且实现了OrderBy,Limit下推等一系列优化规则;同时在一些聚合函数场景下,SQL支持通过分布式计算来优化查询计划的执行,这里暂不一一展开。
相信通过本文的介绍,大家已经对使用SQL引擎访问百度智能云天工TSDB有了一定的了解。目前,百度智能云团队仍在不断完善TSDB上的SQL生态,比如通过JDBC/ODBC来连接TSDB等。未来,SQL生态将延伸到天工的其他产品上,比如物管理服务等,从而实现天工产品的多数据源一站式SQL查询。
