我们不生产“报警”,我们只是“报警”的搬运工
百度云智能运维产品(Noah)的监控系统(Argus)是保障百度内外服务高可用的基石。它具有诸如机器监控、实例监控、HTTP监控、域名监控、日志监控、自定义监控等多种监控手段,具备“海陆空”全方位的监控能力,让服务异常无处遁形。
如果你看过本公众号之前的系列文章,相信你会觉得我所言非虚。
然而如此强大的监控系统所产生的“辣么多”报警,如果不能及时精准地送达给运维人员,那么一切都还只是个传说。今天我们就聊聊报警如何送达的问题。
注意,我们今天不谈报警,我们只谈报警的搬运工——百度云Noah通告平台。
一个都不能少
报警不同于普通的通知,它反映的是线上服务即将或正在遭受损失。如果我们把核心报警搞丢了,造成线上故障得不到及时解决,这个责任是巨大的。由于报警系统天然就这样要求高可靠性,因此我们奉行“at-least-once”的投递原则,确保报警至少有一次能成功抵达用户,做到“该报的报警一个都不能少”。
为了实现这个目标我们经历过不少坑。
-
机房网络连通性问题 我们发送报警要依赖四个底层发送网关(电话网关、短信网关、IM网关、邮件网关)来向用户发送消息,如下图所示。由于公司网络环境的原因,这些网关部署在某些特定机房,和上游的监控系统部署在不同机房中,这样机房间的网络拥塞或抖动将直接影响报警发送。 解决这种问题,可以将底层发送网关主备部署到不同的机房,由上游系统重试解决。也可以考虑建设额外的网络路由通路,例如机房A到B不通时,绕经机房C “曲线救国”。具体选择何种策略,要依据不同的网络现状而定。
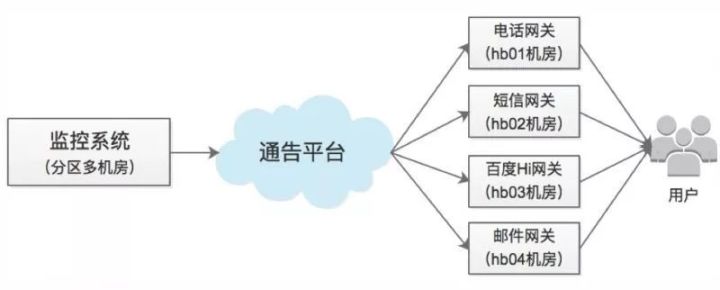
-
限流问题 资源永远是有限的。对我们来说底层网关的发送能力是瓶颈所在,尤其是电话网关,线路资源非常宝贵,有明确的路数限制(例如100路)。这样当某业务的报警量很大时,它的报警将用光有限的发送资源,将导致其他业务的重要报警发送延迟甚至失败。 因此,需要对不同业务的报警量进行限流,避免单业务报警量过大影响其他业务。
-
报警追查问题 监控系统中关于如何报警有多种配置,例如报警最大次数、报警允许等待时长、报警屏蔽等,这些配置都会影响报警发送行为。经常有用户反馈报警不符合预期,例如“该收的报警没有收到,不该收的报警却收到了”等这种咨询问题,其实往往都是由于报警配置导致的,并非系统功能不正常,因此我们面临很多报警追查的需求。 为此,我们将报警从产生到最终发送整个生命周期中的处理历史都记录下来,让用户像查询快递物流信息一样去追查报警处理历史。我的工作是不是真的很像快递搬运工(偷笑.jpg)!
若报警只如初见
随着业务的发展,我们发现报警量越来越大。通告平台每天都面临百万级的报警量,而这些报警中却有大量相似、重复的冗余报警。导致核心报警淹没在大量冗余报警中,极易造成报警遗漏。
如果遇到骨干网拥塞或数据中心故障,那报警量就需要再加几个数量级,这就是传说中的报警风暴,风暴期间运维人员的手机、邮箱迅速会“爆”掉。据说以前有人根据报警短信的响铃频率来判断故障是否恢复,不管这是真事还是笑谈,他的窘境可见一斑。
因此,报警收敛成为了监控报警领域面临的一个共同命题。目前,业界一般的策略是分析报警内容,按照相同关键字进行报警合并。这种策略往往效果很差,因为事实上很多关联报警的内容本身并不包含相同关键字。
针对这一问题我们逐渐演化出两类策略。
1.分维度报警合并策略,即按照报警维度属性(机房、机器、实例、服务等)合并。
2.基于关联挖掘的合并策略,即采用离线数据挖掘或机器学习的方式,从历史报警中挖掘出具有关联关系的监控策略,然后将相关联监控策略下的报警进行合并。
优雅的外表
经过合并后的多个报警,如何友好展示是另一个随之而来的问题。如果把原始报警内容堆叠到一起展示的话,用户将很难理解。毫无疑问,需要对这些原始报警的内容进行抽象概括以友好显示。我们将这一过程称之为“报警渲染”。
-
举个例子。
-
在一个服务集群下配置监控策略Rule_A,该策略下在一个短期时间窗口内共有110条报警, 如图所示:

经过报警合并,最终渲染为一条报警,展示如下:
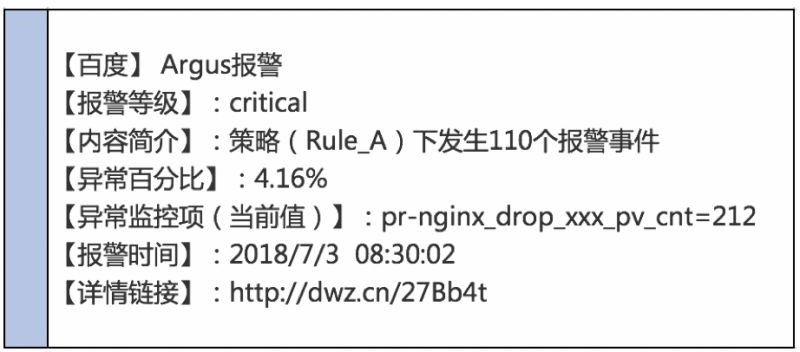
从最终的报警内容中,运维人员可以快速了解报警的严重程度、触发报警的监控策略、影响范围、报警时间等信息。我们针对不同的合并策略分别有不同的渲染模版,目的就是让运维人员能快速准确地获取到报警信息。
另外,对于电话报警,渲染逻辑要更加复杂些,因为报警是以语音的形式触达用户的,受TTS技术所限,很难把形如“pr-nginx_xxx_pv_rule”的策略名,通过电话语音播报给用户,即使播放出英文读音,也会让人莫名其妙。因此我们定义了若干简化的语音模板,只播报核心概要内容,同时提醒用户关注短信、邮件等其他渠道获取报警详情。
7*24值班也能睡个安稳觉
刚刚我们聊了报警风暴问题,它往往是由机房级故障或者网络故障触发大量的冗余报警导致的。而实际上我们观察到还有一个问题同样能带来报警冗余——那就是报警接收人配置过多。
很多业务线将多个运维成员都配置到报警接收人里,而实际上运维人员是轮流值班的,非值班人员完全没有必要接收这些报警,这也造成了资源浪费。因此,我们集成了值班功能,支持设置值班周期、交接班时间、值班提醒,多种值班角色,每天动态地将报警发送给值班人,这减少了一大批冗余报警。
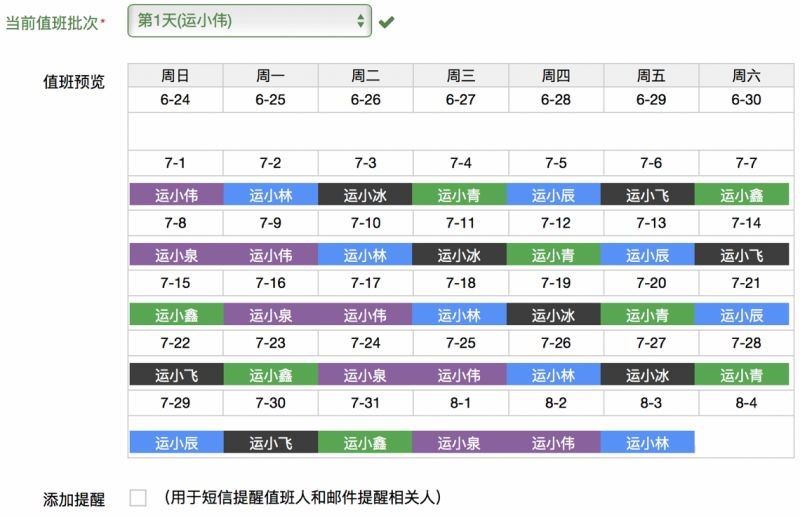
另外,为了确保核心报警能得到及时响应并有效解决,我们引入了“报警升级”,即一个报警如果没有在限定时间内得到处理的话,那么该报警将自动升级到更高一级的接收人那里。
看个示例,如下图:

报警发送给值班人后,如果该值班人在2分钟内没有认领或者在10分钟之内没有处理完成,则自动把该报警发送下一级接收人,如图中的yunxiaolin、yunxiaobo,并直接发送电话报警。如果他们在10分钟之内没有认领或者20分钟之内没有处理完成该报警,则继续升级到下一级接收人,如图中的yunxiaoyu。
值班人收到报警后要回复正确的指令来“认领”或“完成”该报警,我们借此来判断该报警是否继续升级。假如你认为报警足够重要的话,你可以设置多级升级,甚至到“总裁”(偷笑.jpg)!
总结
今天我们一起聊了百度云Noah通告平台遇到过的沟沟坎坎,有如何发报警的基础问题,有报警风暴时报警压缩、报警渲染的难点问题,也有我们在on-call轮值和报警升级场景下的思考。
作为报警的“搬运工”,我们始终相信“简单”的事也可以做得不同!希望我们的努力能让运维兄弟们过得更轻松一点,幸福一点。
目前平台还在持续进化中,欢迎大家积极留言共同交流!
')}
