亚马逊云科技推进云原生数据战略全面服务化,普惠150万企业数据创新
企业与组织管理的数据正在经历爆炸式的增长。研究表明,未来三年(到2024年)创建的数据量将超过过去30年创建的所有数据量。数据的规模在不断扩大的同时,其种类也变得越来越多样化。客户正在存储和分析来自各种来源的数据,包括来自数字媒体与社交网络的数据,来自物联网的数据,以及在线交易、财务分析、基因组学研究的数据等。有效利用数据价值的数据驱动型企业,可以做出更好、更明智的决策,实现更快、更高效的发展,并能不断驱动业务创新,保障业务的稳定,控制风险。

亚马逊云科技通过为客户提供全面、敏捷、安全以及高性价比的云原生数据服务
已助力150万客户成为数据驱动型企业
随着企业云上数据类型和规模不断增长,数据旅程的各个阶段都需要由云原生数据基础设施来实现赋能,以提升系统的效率、可用性和可扩展性,并降低成本。云原生数据基础设施包括数据库、分析工具以及机器学习。专门为数据时代构建的云原生数据库可以帮助企业降低成本、提高性能并加快创新步伐。其次,通过先进的分析工具,能够大规模处理结构化、非结构化和流式数据,为每项分析工作提供最佳的性能和成本,利用云原生的机器学习服务,为数据基础设施深度赋能。同时亚马逊云科技数据服务的Serverless特性能帮助用户构建更简单易用、低门槛、弹性的数据基础,并能稳定、高性能地应对不可预测的工作负载。

使用专门构建的工具服务为各类工作负载提供服务
应对数字时代的企业挑战,亚马逊云科技基于自身的15年的数据创新经验、技术优势与客户案例积累,为客户提供完整的端到端数据战略实施解决方案。
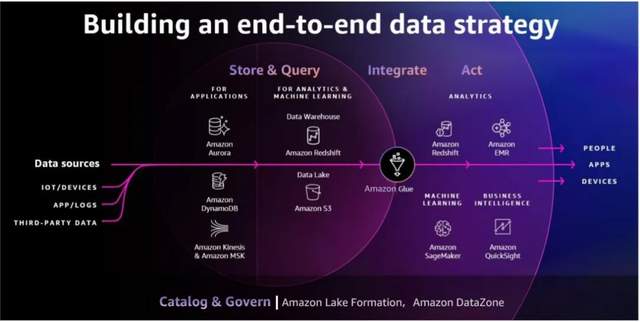
以Amazon Aurora和Amazon DynamoDB为典范的云原生数据库产品,能够助力企业搭建一套可弹性伸缩、高性能、安全的数据架构,应对跨区域部署与运维工作的挑战,并且避免传统架构在业务增长时的中断问题,实现应用伴随业务自动扩缩与低运维。通过Amazon Glue等数据集成工具,将所有这些数据流转到数据分析服务中进行分析需求, 对于任何类型、任意规模的数据以及面向任何阶段的用户,都可以借助亚马逊云科技专门构建的云原生数据分析工具,如Amazon EMR,Amazon Redshift,Amazon OpenSearch等,快速、敏捷的开始搭建适合自己的数据分析场景,深层次的机器学习,自动化的机器学习,如Amazon SageMaker,可以为用户在可拓展的情况下打造学习模型,并进行部署。
在数据的分类和管理方面,亚马逊云科技推出的新的解决方案Amazon DataZone是实现这一目标的新选择。通过打破数据孤岛,实现优势整合与成本效益最大化。任何阶段的企业都可以从这种敏捷的架构中快速获益,轻松打破数据及技能孤岛,并以迭代及增量的方式获得数据分析的敏捷性,缩短企业提取数据价值的创新周期。
本次re:Invent大会中,亚马逊云科技正式推出Amazon Athena for Apache Spark,对于Amazon Athena的客户来说,如果想使用Apache Spark进行复杂的数据的分析和处理,但是不想建立太多的基础数据跟上分析数据的要求,并且想同步使用Amazon Athena SQL的应用,只需1秒钟的时间,用户就可以运行交互式的数据查询,它比其他类似的解决方案提供商提供的解决方案快75倍。同时,它可以非常深入地跟亚马逊云科技其他解决方案集成,比如Amazon SageMaker、EMR这些已经完整地很好地整合在一起,用户可以把这些解决方案应用在一起,再来开发所需要的进一步的应用。

大会中亚马逊云科技还发布了新的Amazon Redshift Integration for Apache Spark,用户可以用10倍更快的速度去进入Apache Spark完成操作,快速而敏捷的实现分析与机器学习。

亚马逊云科技把各种不同的工具呈现在客户面前,当客户需要的时候可以用。这些服务可以帮助业务成长的时候不受到任何的来自于技术层面的限制。
借助云原生数据服务打造极致性价比
亚马逊云科技的产品及服务在卓越性能的前提下,能够帮助客户实现一系列灵活的成本优化。托管服务几乎不需要运维,相对于自建的高运维成本,更具有性价比;通过Serverless产品,提供了对不可预测负责的最佳性价比;智能分层存储功能、SPOT实例、Graviton集成等功能提供的性价比优化,比如DynamoDB Standard IA,ElastiCache分层存储,EMR on Spot实例,Redshift Serverless,Aurora on GV2等。
其中Amazon DocumentDB是一款兼容MongoDB的文档数据库,它可以自动向上拓展到每个数据集群达到64 TB。有数十万的数据用户,包括Venmo、Liberty Mutual还有UNITED都是用这个解决方案一键就可以处理用户的需求。为此进一步的推出了Amazon DocumentDB Elastic Clusters,不管是什么样的尺度要求,容量的要求,都可以拓展数据的需求,它可以自动上行拓展存储,几分钟即可完成,用户不需要去担心运维或者迁移的复杂度。弹性数据集群可以非常灵活地来满足数据管理的需求,并减少相关的维护成本。

借助机器学习,摆脱枷锁,加速创新
亚马逊云科技的很多产品功能特性都具备了机器学习的加持,让用户的工作变得更智能。Amazon Deveops Guru使用 ML 来检测异常运维模式,以便在运维问题影响客户之前识别这些问题,并给出建议。Amazon S3 Intelligent-Tiering 智能分层存储,自动的降低用户的存储成本。当然,还有首个云上机器学习IDE Amazon SageMaker可以让客户来建造并且培训和配置所有的,每一步都会提供帮助。成千上万的用户用Amazon SageMaker,每个月可以有数万亿的预测,很多客户都使用Amazon SageMaker解决问题,利用企业自身的数据来制造自身定制化的数据模型,比如有些药物的发现,大部分模型是数字型的,80%都是没有结构,或者是只有半结构型的;比如地质方面的数据,地质空间数据的处理难度很高,数据量不仅庞大,且没有组织,因此在进行编写代码的时候,会出现大量的问题。
非常复杂的数据处理即使对于数据科学家来说也是非常困难的,而现在通过Amazon SageMaker可以支持新的地质空间的机器学习。通过这些他们可以适用地质方面的数据,只用几次的点击就可以。它是针对某种物体所建造的,可以让你进行大量的数据处理,他们有一些直观的数据,3D的地图上可以进行互动的操作。他们也可以让我们很多新的地方都可以进行模型的制作。


*亚马逊云科技专家正在分析地理空间的推理服务
打造安全可控的云上数据创新
数据的影响力是非常重要的,每个组织每个层面都可以通过透彻地理解这些数据,然后不断地引领对过去有颠覆性的、前瞻性的、领导性的新的解决方案,因此可靠和安全就显得非常重要。
亚马逊云科技的多数云原生数据服务都支持Multi-AZ配置,具备跨多个可用区的高可用。比如Amazon Aurora Global Database全球数据库,让应用具备全球扩展能力。亚马逊云科技拥有最多的云原生数据服务Serverless无服务器选项,包括数据库、数据仓库、大数据分析、实时数据、数据集成、机器学习等选项。业务与开发可以专注于自身的业务与应用程序,将底层数据基础设施交给云端,来为不可预测的工作负载提供极致的弹性扩缩。
Amazon GuardDuty通过数据学习来监控数据的行为并提供详细的安全侦察结果以实现可见性和补救,而通过新推出的Amazon GuardDuty RDS Protection方案,用户只要一个点击即可利用机器学习运行智能的威胁检测来保护数据库,所有的这些信息都集成在一个企业级的能力上为客户服务。这个也为数据的保护提供了基础,客户可以在数据不同的存储方面可以把这些连接起来,它直接与 Aurora 集成以直接访问数据库事件而无需修改数据库配置,并且旨在不影响数据库性能表现。

本次大会诸多创新进一步丰富了亚马逊云科技数据家族图谱,通过完整的全链路云原生数据服务家族,将赋能亚马逊云科技进一步加大在降低使用门槛/开放集成宽度方面的领跑。
点击链接:https://www.awsevents.cn/reInvent2022/?s=7982&smid=14988,欢迎回看2022 re:Invent 全球大会精彩内容。
