在上一篇《容器化实践指南 | 迈出容器化的第一步:集群管理(上)》中,我们介绍了Kubernetes的节点如何构成一个集群。本篇将在此基础上,继续介绍Kubernetes集群的容器网络架构。

当Kubernetes集群完成搭建后,用户的容器就可以运行在众多的工作节点之中,那么接下来就需要确保这些容器之间可以互相访问或接受来自外部的访问。虽然我们在搭建集群时就已经确保了所有工作节点在网络上是互通的,但是由于同一个节点上可能同时运行多个容器,并且容器本身也随时可能在节点之间移动,因此Kubernetes需要一套容器网络方案来保障访问某个指定容器的流量可以正确地到达该容器,并且不同容器在接收请求时不会出现路由冲突。
Kubernetes网络基本的部署调度单元:Pod
在说明常见的容器网络方案之前,我们需要先理解一个Kubernetes中最基础的概念:Pod。
简单来说,Kubernetes中的基本管理单元并不是一个个独立的容器,而是一个或多个相关容器组成的容器组,称为Pod。通常情况下,一个Pod即用户部署的一个服务单元,比如一个数据库服务、一个Web服务等。如果用户的一个服务单元中存在多个独立运行的组件,那么这些组件就可以部署在该Pod的不同容器中,从而在组件解耦的基础上便于对多个容器进行统一管理。
Pod在英文中的原意是豌豆荚,也非常形象地表达出了Pod(豆荚)与容器(豆子)之间的关系。

关于Pod的管理未来我们将会进行更多的阐述,单从容器网络的角度来看,每一个Pod即是一个独立的最终访问单元。因此Kubernetes的网络架构中有一个最基本的设计原则:每个Pod拥有唯一的IP地址。这个Pod IP将被Pod中的所有容器共享,而集群内的其它Pod则可以通过该Pod IP正确访问到对应容器。
在理解这个基本原则之后,我们也就不难理解,容器网络方案需要解决的问题其实包括以下3个:
- 同一个Pod中的多个容器如何通讯
- 同一个工作节点上的Pod之间如何通讯
- 跨不同工作节点的Pod之间如何通讯
同一个Pod中的多个容器间通讯
在Kubernetes的设计中,一个Pod内的所有容器共享同一个网络命名空间(Network Namespace,后文中简称为netns),因此它们之间可以直接通过”localhost” + 端口互相访问。
但需要注意的是,由于Pod内的容器共享同一个netns,因此为了避免访问冲突,这些容器各自使用的端口必须唯一。比如说容器A占用了80端口,那么同一个Pod中的容器B就不能再使用该端口了。
为了便于理解,我们通过一个简单的例子说明:
- 我们创建一个Pod,Pod中存在两个容器,其中一个运行Nginx作为反向代理,另外一个运行简单的Web应用程序
- 可以定义Nginx的容器端口为80,定义Web应用程序的容器端口为9000,假设外部访问该Pod的请求都使用80端口
- 在Nginx容器中通过配置文件定义:通过80端口输入的请求将被转发到本地端口9000
- 所有访问该Pod 80端口的请求,都将被发往Nginx容器,然后再被转发到Web应用容器的9000端口

同一个工作节点上的Pod间通讯
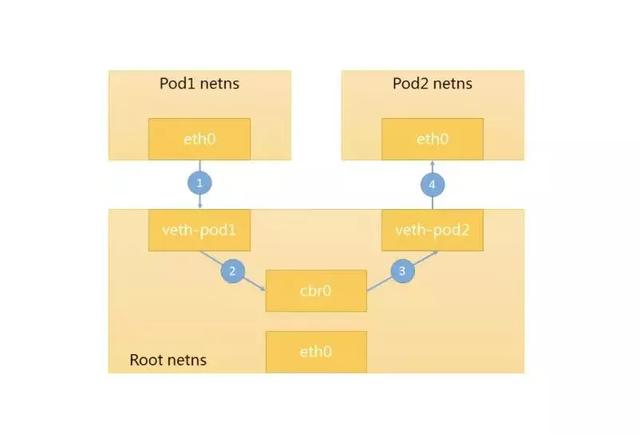
在Kubernetes集群中的每一个工作节点(针对Linux操作系统),都会有一个根网络命名空间(root netns),工作节点上的根网络设备(eth0)就在这个root netns下。对于每一个部署在节点上的Pod,其自身都有一个独立的netns(即前文提到的由Pod内所有容器共享的网络命名空间),Pod本身不需要感知到节点主机上真实的网络设备,而是拥有自己的虚拟根网络设备(同样叫做eth0)。
Pod自身的netns通过一个Linux虚拟网络设备 veth 连接到root netns中,该虚拟网络设备通常被命名为veth***,在节点中通过ifconfig或者ip a等命令就可以列出该节点上所有的veth。同时每个节点中会创建一个专用的以太网桥(通常称为 cbr0),这个网桥的作用类似于交换机,通过mac寻址,将访问节点内Pod IP的请求投递到正确的物理地址。
当一个网络数据包要从Pod1发送到Pod2,它会经历以下流程:
- 首先数据由Pod1中netns的网络接口eth0离开,通过veth-pod1进入root netns
- 然后数据被转到网桥cbr0中,cbr0通过ARP请求询问:“谁拥有这个IP?”
- verth-pod2答复说“我拥有这个IP”,于是cbr0将数据包投递给verth-pod2
- 最后数据包通过verth-pod2,被转发到Pod2的netns
跨不同工作节点的Pod间通讯
最复杂的情况就是在不同节点上的Pod需要互相通讯,由于Pod本身会经常在不同节点间漂移,因此Pod对应的IP地址也需要动态地路由到不同节点上。
在公有云环境下,最常用的方案就是直接通过VPC所提供的路由表功能帮助网络流量到达正确的目的地。由于VPC内的所有流量都通过VPC本身提供的虚拟交换机进行转发,当一个Pod需要访问另一个Pod时,如果节点发现访问对象的IP地址不在本节点上,流量就会通过节点的根网络设备发送到VPC中的虚拟交换机,交换机再通过路由表规则将流量正确转发到目标Pod IP所在的节点上,再由节点内的netns转发到目的Pod。
百度云容器引擎CCE即采用了这种方案,CCE服务将会帮助用户动态维护路由表规则,将容器网络中的地址通过路由表规则映射给集群内的各个节点IP,从而确保访问Pod的流量转发到正确的节点中。这种方案无需经过额外的Overlay网络层,因此具备较高的网络性能。
如果用户不在公有云环境使用Kubernetes,或者不具备自动更新路由表规则的能力,就需要在Kubernetes中集成其它的网络方案,其中最常见的包括Flannel和Calico。
- Flannel是一种overlay网络方案。简单来讲,就是通过在节点中部署一个叫做flanneld的进程来构建一个跨节点的容器网络空间,该进程通过etcd来管理所有Pod的地址资源,记录每个Pod所在的节点地址,然后将节点内通过cbr0向外发送的数据包再次打包,利用集群网络将数据包发送到目标flanneld上,从而实现Pod跨节点的通讯。但是由于flannel方案本身引入了多个网络组件,且在通讯过程中需要对数据进行再次打包,因此会引入一些网络的时延损耗。
- Calico方案则是利用每个节点的Linux Kernel来实现一个vRoute进行数据转发,每个vRoute通过BGP协议把自己所在节点上运行的Pod路由信息向整个Calico网络内传播,这样保证最终所有的Pod间的通讯都可以直接通过IP路由的方式实现。Calico网络方案直接利用节点所在的网络结构,不需要额外的隧道或者Overlay网络,因此同样具备较高的网络性能。但是Calico本身的部署相对来讲比较复杂,对用户的要求较高。
下期内容预告
本期我们介绍了容器网络所解决的问题以及常见的方案,希望可以帮助大家更好地理解Kubernetes的网络架构。下期我们将带来集群管理的最后一部分内容:存储管理。敬请期待!
关注百度云微信公众号,了解和体验百度云容器引擎CCE。
')}
